AWS EMR: Unleashing the Power of Amazon’s Elastic MapReduce
Introduction
In today’s data-driven world, organizations are grappling with an ever-increasing volume, velocity, and variety of data. The ability to process and analyze this vast sea of information has become a critical differentiator in the marketplace. However, setting up and managing a big data infrastructure can be complex, time-consuming, and expensive. This is where AWS EMR (Amazon Web Services Elastic MapReduce) comes into play.
AWS EMR is a game-changer in the big data landscape, offering a cloud-native solution that simplifies the process of running large-scale data processing frameworks. Whether you’re a startup looking to analyze user behavior or a large enterprise processing petabytes of sensor data, AWS EMR provides the tools and scalability needed to derive insights efficiently and cost-effectively.
In this comprehensive guide, we’ll dive deep into AWS EMR, exploring its features, architecture, use cases, and best practices. We’ll also compare AWS EMR with traditional on-premises solutions and examine some alternatives in the market. By the end of this article, you’ll have a solid understanding of how AWS EMR can revolutionize your data processing workflows and help you unlock the full potential of your data.
So, let’s embark on this journey to discover how AWS EMR is unleashing the power of big data processing in the cloud.
What is AWS EMR?
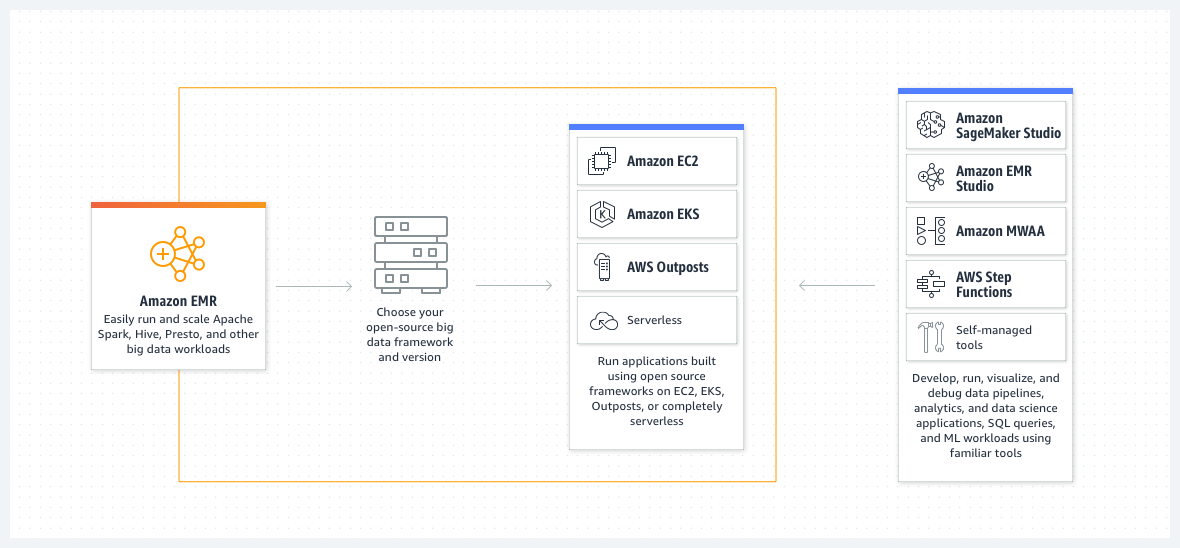
AWS EMR (Elastic MapReduce) is a cloud-based big data platform that simplifies large-scale data processing. It’s a managed cluster platform that runs popular distributed frameworks like Apache Hadoop, Spark, and Presto. AWS EMR automates cluster setup, configuration, and tuning, allowing users to focus on data analysis rather than infrastructure management.
AWS EMR’s flexibility lets users choose from various instance types and customize clusters for specific needs. It supports a wide range of open-source tools and integrates seamlessly with other AWS services, enabling comprehensive data workflows. The AWS EMR platform is cost-effective, with per-second billing and Spot Instance support, and includes tools for monitoring and optimizing cluster utilization.
Security and compliance are built-in to AWS EMR, with features like encryption, authentication, and fine-grained access controls. AWS EMR is compliant with several industry standards, making it suitable for regulated industries. By making advanced analytics capabilities accessible to organizations of all sizes, AWS EMR effectively democratizes big data processing in the cloud.
(Source: Amazon Web Services, aws.amazon.com)
Key Features of EMR
- Scalability: EMR allows you to scale your cluster up or down based on your processing needs.
- Cost-effective: Pay only for the resources you use with per-second billing.
- Flexibility: Choose from a wide range of big data tools and frameworks.
- Integration: Seamlessly integrate with other AWS services.
- Security: Benefit from built-in security features and compliance certifications.
Note:
Looking to understand the broader landscape of cloud computing? Check out our article on What is Amazon Web Services (AWS) in Cloud Computing? for a comprehensive guide on how AWS powers modern cloud solutions, including services like EMR.
Getting Started with AWS EMR
Setting up an EMR cluster is straightforward. Here’s a quick overview of the process:
- Choose your cluster configuration
- Select the applications you want to run
- Configure instance groups
- Set up security and access
- Launch your cluster
Let’s look at an example of launching a simple EMR cluster using the AWS CLI:
aws emr create-cluster --name "My EMR Cluster" \
--release-label emr-6.5.0 \
--applications Name=Spark \
--ec2-attributes KeyName=myKey \
--instance-type m5.xlarge \
--instance-count 3 \
--use-default-roles
This command creates a 3-node EMR cluster with Spark installed, using m5.xlarge instances.EMR Architecture and Components
Understanding the architecture of EMR is crucial for effective use. An EMR cluster consists of three main components, each playing a vital role in the distributed processing ecosystem:
Master Node
The master node is the command center of your EMR cluster. It manages the cluster and coordinates the distribution of data and tasks to the core and task nodes. Key functions of the master node include:
- Running the primary daemons like ResourceManager for YARN and NameNode for HDFS
- Tracking the status of jobs and monitoring the health of the cluster
- Hosting the web interfaces for various cluster components
- Managing the distribution of work across the cluster
For example, when you submit a Spark job to your EMR cluster, the master node decides which core or task nodes will execute various parts of that job.
Core Nodes
Core nodes are the workhorses of your EMR cluster. They perform two critical functions:
- Running the DataNode daemon to store data in HDFS (Hadoop Distributed File System)
- Executing the NodeManager daemon to run task components
Core nodes form the backbone of your data processing capabilities by:
- Storing data reliably across the cluster using HDFS
- Providing computational resources for running tasks
- Communicating with the master node to receive work assignments and report progress
A typical EMR cluster will have at least one core node, but larger clusters may have hundreds or even thousands of core nodes to handle massive datasets.
Note:
Curious about cost-saving strategies for your EMR clusters? Explore our article on Understanding AWS Reserved Instances to learn how you can optimize your spending while running workloads on AWS.
Task Nodes
Task nodes are optional components in an EMR cluster that add extra flexibility to your processing capabilities. Key characteristics of task nodes include:
- Running only the NodeManager daemon to execute tasks
- Not storing data in HDFS, making them easily added or removed without risk to data integrity
- Ideal for handling temporary increases in workload or accommodating peak processing demands
Task nodes are perfect for scenarios where you need to scale up your processing power quickly without affecting your core storage capacity. For instance, you might add task nodes to handle end-of-month reporting jobs that require additional compute resources.
Putting It All Together
The interplay between these components creates a robust, scalable system:
- The master node receives a job and coordinates its execution across the cluster.
- Core nodes store the data and perform the bulk of the processing work.
- Task nodes (if present) provide additional computational power for executing jobs.
This architecture allows EMR to efficiently handle a wide range of big data processing tasks, from simple data transformations to complex machine learning workflows. By understanding these components, you can better optimize your EMR clusters for performance and cost-effectiveness.
EMR Use Cases
AWS EMR’s versatility makes it suitable for a wide range of big data use cases:
- Log analysis
- Web indexing
- Data transformations (ETL)
- Machine learning
- Financial analysis
- Bioinformatics
- Social network and clickstream analysis
For example, a media streaming company might use EMR to analyze viewing patterns:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("ViewingPatternAnalysis").getOrCreate()
# Load viewing data
viewing_data = spark.read.csv("s3://your-bucket/viewing-data.csv")
# Analyze viewing patterns
popular_shows = viewing_data.groupBy("show_id").count().orderBy("count", ascending=False)
popular_shows.show()This simple PySpark script, when run on EMR, can process millions of viewing records efficiently.
EMR vs. Traditional On-Premises Solutions
When it comes to big data processing, AWS EMR stands out from traditional on-premises solutions in several ways. Gone are the days of hefty upfront hardware investments; with EMR, organizations can dive into data processing swiftly and with minimal initial outlay. The platform’s dynamic scaling adjusts resources on the fly, ensuring you’re always operating at peak efficiency.
But EMR’s true power lies in its ecosystem integration. Seamlessly connecting with services like S3, Glue, and Athena, EMR creates a comprehensive data environment that’s hard to match with on-premises setups. This integration, combined with AWS’s management of the underlying infrastructure, frees your team to focus on what really matters: extracting valuable insights from your data.
Consider these key advantages of EMR:
- Rapid deployment: Spin up clusters in minutes, not weeks or months
- Cutting-edge tools: Access the latest big data technologies, regularly updated
- Global reach: Process data across multiple regions with ease
- Reduced maintenance: Let AWS handle the infrastructure, while you handle the insights
While on-premises solutions may offer more hardware control and meet certain compliance needs, EMR’s flexibility, scalability, and cost-effectiveness make it a compelling choice for organizations ready to harness the full potential of their data.
EMR Pricing and Cost Optimization
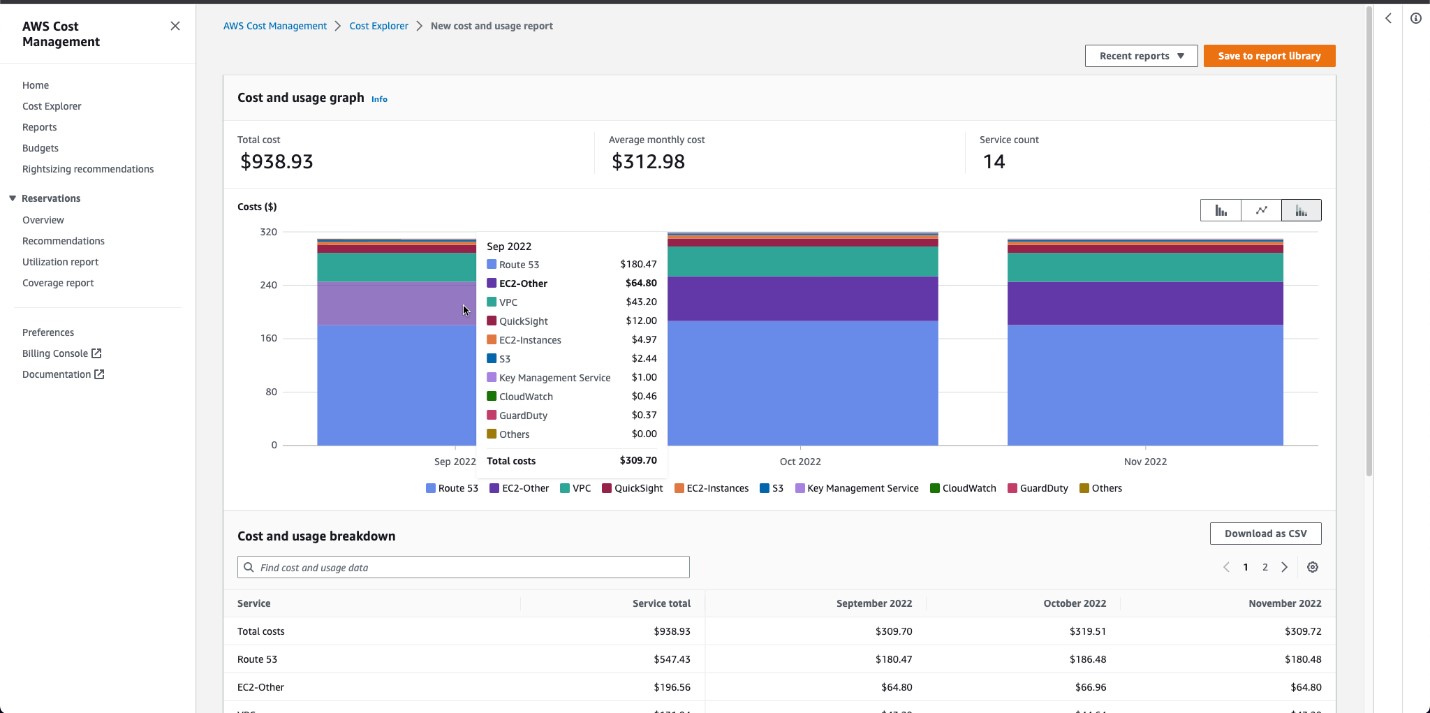
EMR’s pricing model is straightforward, based on EC2 instances used plus a per-second EMR charge. To optimize costs, organizations can employ several strategies. Spot Instances for task nodes offer significant savings on interruptible workloads, while Auto Scaling ensures efficient resource use by adjusting cluster size automatically. Choosing the right instance types for specific workloads and utilizing EMR Managed Scaling for dynamic resource adjustment further enhance cost-effectiveness. Storage optimization plays a crucial role too, with S3 recommended for long-term storage and HDFS for temporary data. For predictable workloads, Reserved Instances can offer substantial savings through long-term commitments.
Note:
New to EC2? Dive into our article on Exploring the Fundamentals of Amazon EC2 Instances to better understand the backbone of AWS infrastructure and how it supports EMR and other big data workloads.
Regular monitoring using AWS Cost Explorer and EMR’s built-in tools helps identify optimization opportunities. By periodically reviewing and fine-tuning their EMR configurations, organizations can achieve significant cost savings over time while maintaining the platform’s performance and scalability benefits.
Security and Compliance in EMR
EMR offers robust security features for data protection and compliance:
- Network security: EC2 security groups control traffic
- Access management: IAM roles manage permissions
- Data protection: Encryption for data at rest and in transit
- Authentication: Kerberos integration and LDAP connectivity
- Compliance: Certifications including HIPAA, PCI DSS, and ISO standards
- Network isolation: VPC support for secure environments
- Auditing: AWS CloudTrail integration for comprehensive logging
- Fine-grained control: Apache Ranger integration for detailed policies
While AWS secures the infrastructure, customers are responsible for secure application deployment and data management within EMR. These features enable organizations to create a secure, compliant big data environment that balances protection with cloud-based processing flexibility.
EMR Best Practices
To get the most out of EMR:
- Right-size your cluster
- Use appropriate storage options (HDFS, EMRFS, Local File System)
- Optimize your data format (e.g., use Parquet for columnar storage)
- Implement a good monitoring strategy
- Use bootstrap actions for custom configurations
Note:
Want to ensure your EMR workloads meet industry standards? Check out our article on Cloud Compliance Regulations and Best Practices to stay informed on maintaining compliance in the cloud while leveraging AWS services.
EMR Alternatives
While EMR is a powerful tool, it’s essential to consider alternatives to ensure you’re using the best solution for your needs:
Google Cloud Dataproc
Google’s fully managed Spark and Hadoop service offers seamless integration with other Google Cloud services.
Pros:
- Faster cluster startup times
- Integrated with Google Cloud ecosystem
- Preemptible VMs for cost savings
Cons:
- Smaller ecosystem compared to AWS
- Less flexible pricing options
(Source: Google Cloud Platform Blog, cloudplatform.googleblog.com)
Azure HDInsight
Microsoft’s cloud-based big data processing service supports a wide range of open-source frameworks.
Pros:
- Deep integration with Azure services
- Support for a wide range of big data frameworks
- Strong security and compliance features
Cons:
- Can be more expensive than EMR for some workloads
- Steeper learning curve for non-Microsoft shops
Databricks
A unified analytics platform built on top of Apache Spark, offering a collaborative environment for data science and engineering.
Pros:
- User-friendly notebook interface
- Advanced MLOps capabilities
- Multi-cloud support
Cons:
- Can be more expensive than EMR
- Less control over underlying infrastructure
On-Premises Hadoop Clusters
For organizations with specific requirements or existing infrastructure investments, on-premises solutions might be preferable.
Pros:
- Full control over hardware and software
- Potentially lower costs for very large, stable workloads
- Data remains on-premises (compliance requirements)
Cons:
- High upfront costs
- Requires significant in-house expertise
- Less scalable and flexible than cloud solutions
When considering alternatives, evaluate factors such as:
- Your existing cloud ecosystem
- Specific big data tools and frameworks you need
- Cost structure and budget
- Security and compliance requirements
- Team expertise and learning curve
Note:
Looking to scale your EMR workloads efficiently? Read our article on Optimizing Kubernetes with Cluster Autoscaler to discover how autoscaling can enhance resource management for your big data applications on AWS.
Conclusion
AWS EMR offers a powerful, flexible, and cost-effective solution for big data processing in the cloud. Its seamless integration with other AWS services, support for a wide range of big data tools, and robust security features make it an attractive option for organizations of all sizes.
However, it’s essential to consider alternatives like Google Cloud Dataproc, Azure HDInsight, Databricks, or even on-premises solutions depending on your specific needs. Each option has its strengths and weaknesses, and the best choice will depend on your unique requirements, existing infrastructure, and team expertise.
As big data continues to grow in importance, platforms like EMR will play a crucial role in helping organizations extract value from their data. By understanding the capabilities of EMR and its alternatives, you can make an informed decision on the best big data processing solution for your needs.
To learn more about AWS EMR and other cloud technologies, visit our Binadox blog. We regularly post in-depth articles, tutorials, and industry insights to help you stay ahead in the ever-evolving world of cloud computing and big data. Need scalable storage for your EMR workloads? Check out our article on Cloud Storage: A Comprehensive Look at AWS EBS and Its Pricing Model to learn how EBS can optimize both performance and costs for your data-intensive applications.